Announcing table and column output name overrides for data warehouses

Announcing table and column output name overrides for data warehouses
Polytomic supports ELT, ETL, and CDC streaming workloads to data warehouses. Yet source databases and applications have all sorts of naming conventions, so which one should the resulting tables and columns in your warehouse have?
When it comes to naming, consistency is key. Arguments about snake_case versus camelCase are dwarfed by the maddening special-casing in queries to handle a mix of updated_at, updatedAt, and updatedat.
To address this, Polytomic automatically normalizes all names for you using a documented convention.
But exceptions in preferences abound, so today we released options that give you full control of the resulting table and column names, no matter your preferences:
1. By default, Polytomic will automatically normalize names for you per the above convention.
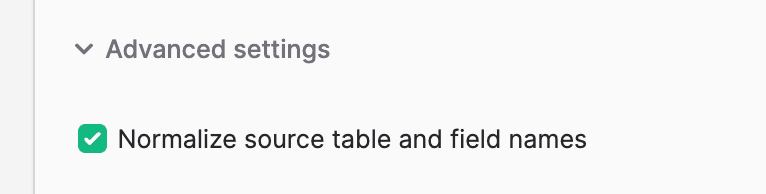
2. However, you now get an option to turn this off per-sync if you don't want any normalization:
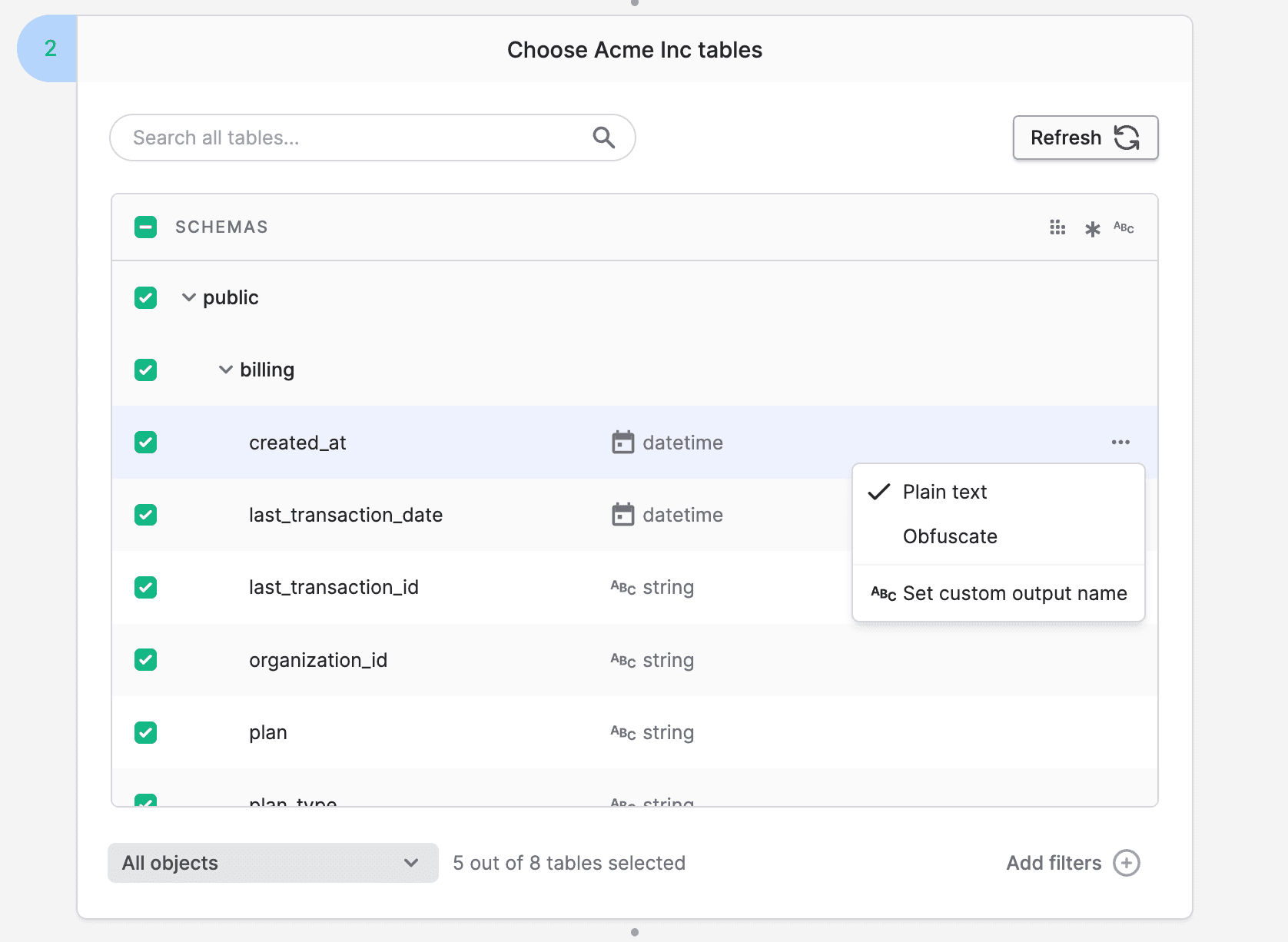
3. For even more fine-grained control, you also have the ability to specify your own custom output names for specific tables and columns of your choice:
With these changes, you now have complete freedom to decide how Polytomic names the tables and columns it writes to your data warehouse. You can see more in our documentation here: https://docs.polytomic.com/docs/bulk-sync-naming-conventions.